Apache Spark Web UI on Amazon EMR
**Update (2018 November 30):** Starting from `emr-5.18.0`, we can access the Spark Web UI through Spark History Server > Show incomplete applications > Click an App ID. An URL example,
Apache Spark is a fast and general engine for large-scale data processing.
It has a web UI that we can use to monitor each Spark job in detail. This is useful for debugging and optimization.
Coupled with Apache Zeppelin, we can have a very interactive web-based notebook environment for Apache Spark, just like Jupyter Notebook.
Thanks to Amazon EMR, we can setup and run a Spark cluster with Zeppelin conveniently without doing it from scratch.
After doing either local port forwarding or dynamic port forwarding to access the Spark web UI at port 4040, we encounter a broken HTML page.
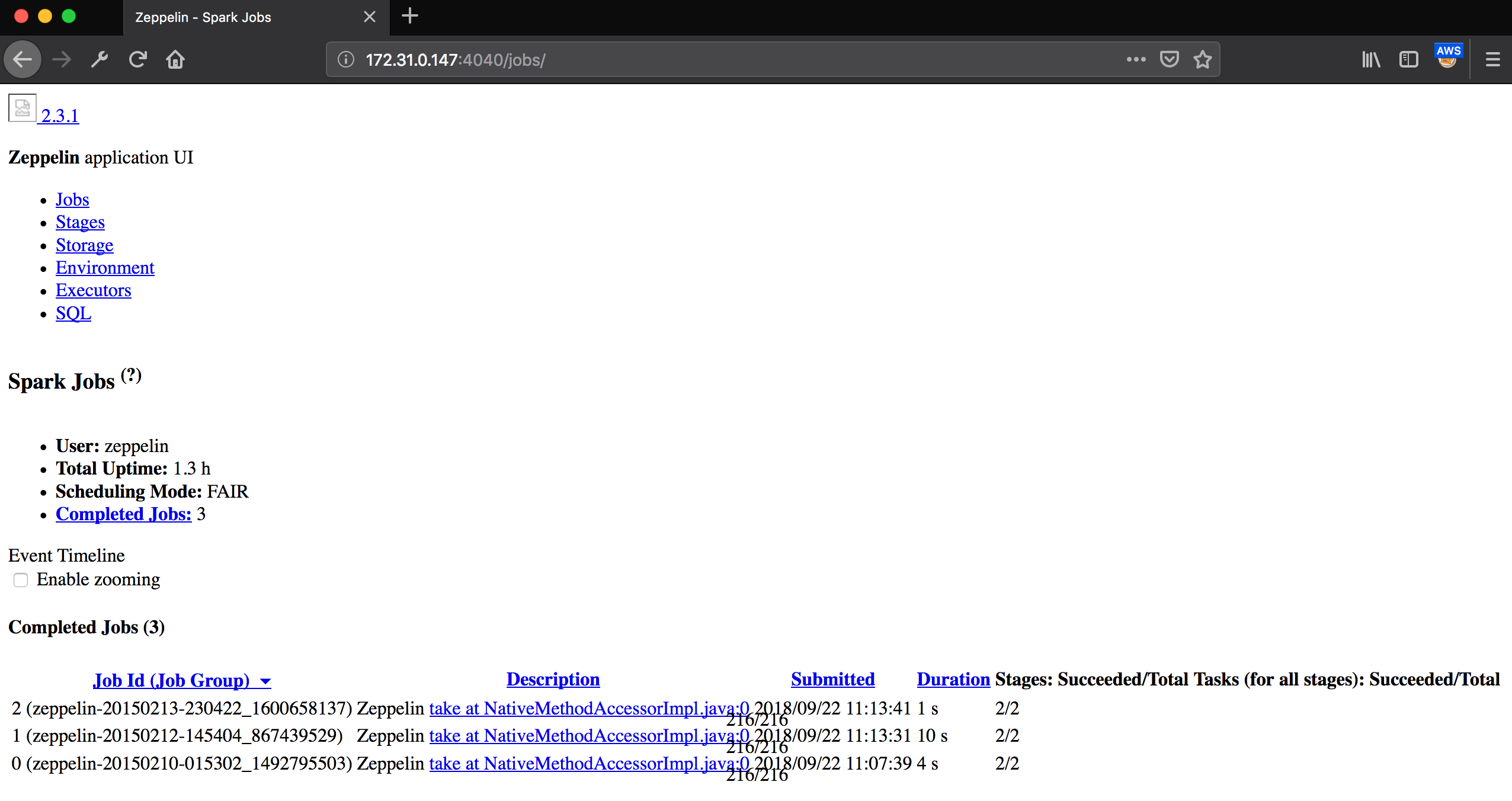
172.31.0.147 is the internal IP of the Spark master instance.
Before we go into the details or for those who want to skip the details, just read the short version below.
Short Version
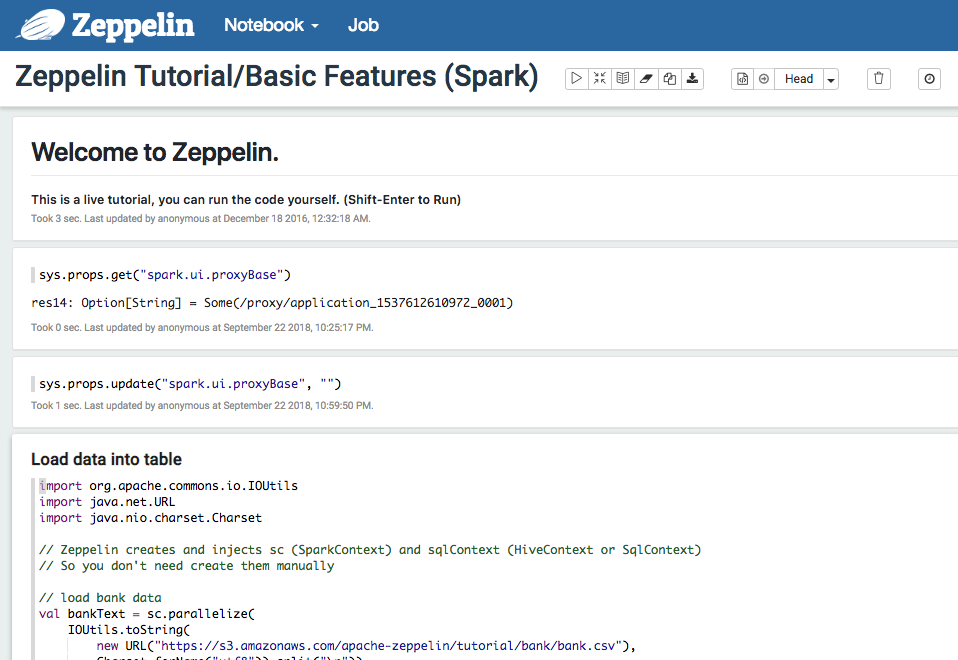
At runtime on Zeppelin notebook or Spark job Scala code, update system properties spark.ui.proxyBase to empty string.
1 | sys.props.update("spark.ui.proxyBase", "") |
Reload http://172.31.0.147:4040 page.
Long Version
Why is Spark web UI not displaying correctly? How to fix it? Let’s look at the page source to find out.
1 | <meta http-equiv="Content-type" content="text/html; charset=utf-8" /> |
Going to http://172.31.0.147:4040/proxy/application_1537612610972_0001/static/bootstrap.min.css will redirect us back to http://172.31.0.147:4040/jobs/.
However going to http://172.31.0.147:4040/static/bootstrap.min.css will unveil the actual file.
We have to find a way to get rid of /proxy/application_1537612610972_0001.
At this point, we can roughly guess it is because of a reverse proxy due to the proxy string inside /proxy/application_1537612610972_0001. To confirm, let’s go to the Spark source code on GitHub and search for bootstrap.min.css.
Eventually this will lead us to UIUtils.scala. To match the Spark version that we are using, select v2.3.1 tag.
1 | // Yarn has to go through a proxy so the base uri is provided and has to be on all links |
Comparing code snippet and HTML snippet above, UIUtils.uiRoot = /proxy/application_1537612610972_0001. The 1st line comment in the code snippet confirms that there is YARN reverse proxy that protects Spark cluster from web-based attacks. YARN is a resource manager that allow us to run Spark in cluster mode.
Also, looking at http://172.31.0.147:4040/environment/ page (Caution: We have to manually go to the link. Clicking the Environment link will just redirect us back to homepage), we can see that spark.ui.filters is org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter. More information can be found inside the doc.
We cannot set spark.ui.proxyBase inside spark-defaults.conf file or APPLICATION_WEB_PROXY_BASE Spark environment variable because the proxy will overwrite everything.
Assuming that we want to avoid configuring the proxy or we do not have the permission to do so, there is a solution that we can take.
On your Zeppelin notebook or Spark job Scala code, update system properties spark.ui.proxyBase to empty string.
1 | sys.props.update("spark.ui.proxyBase", "") |
Reloading http://172.31.0.147:4040 page will show the actual web UI.
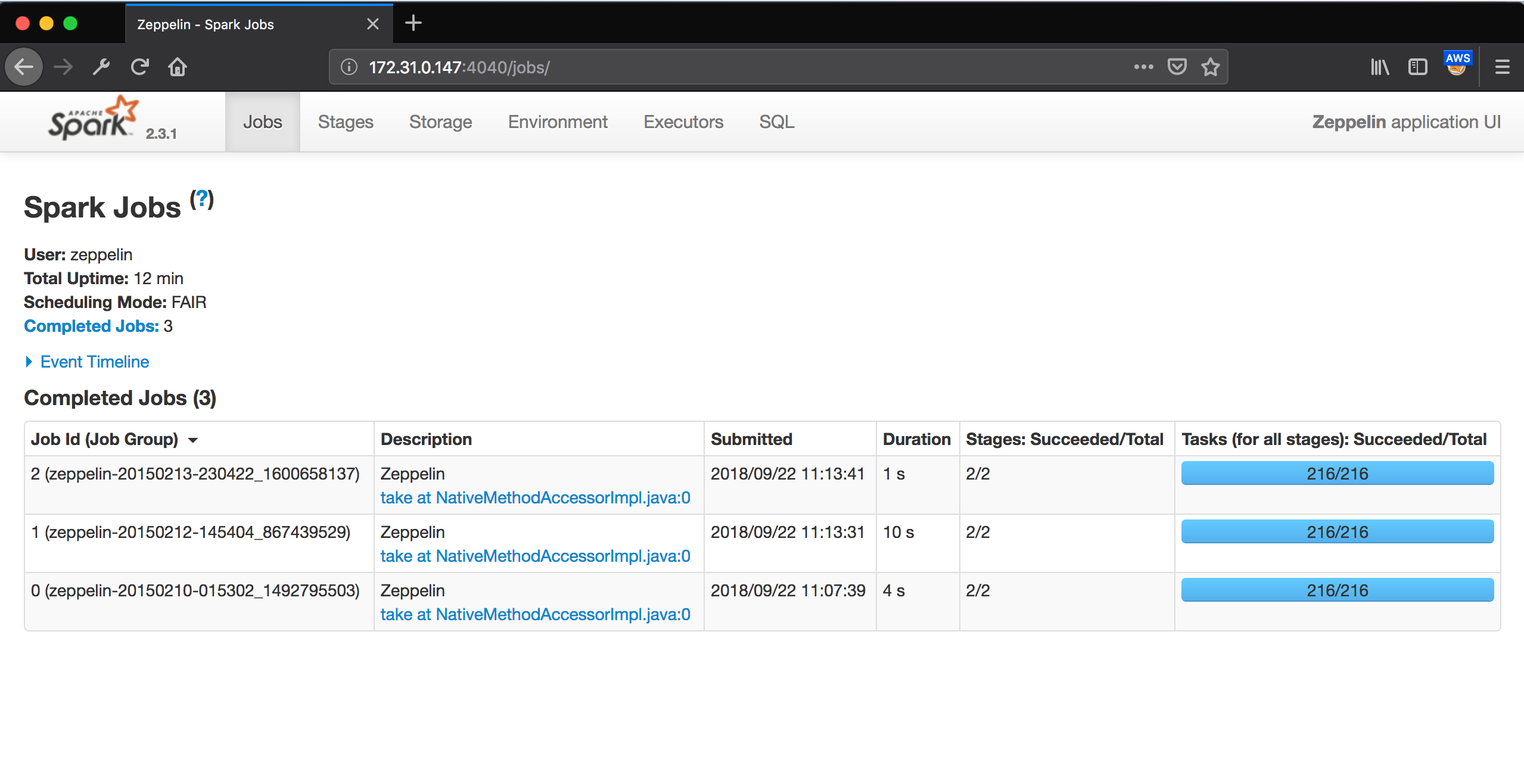
Now we can start having fun doing real work on Spark cluster!